Wearable Sensor Selection, Motion Representation and their Effect on Exercise Classification
Abstract
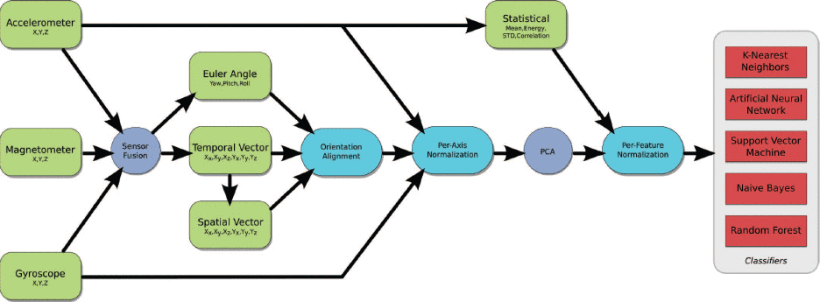
Motion classification using accelerometer, gyroscope and magnetometer sensors have been an important area of exploration for the past decade. Mostly studied in the context of health related applications, the implications of accurate inertial-magnetic motion classification span from continuous daily activity monitoring and remote assessment of patients recovery to athlete optimization and entertainment applications. While much has been done to optimize classification and segmentation algorithms, very little is understood of the effect sensor selection and motion representation has on overall system performance. In this paper, three sensors (accelerometer, gyroscope, orientation), seven motion representations and six classification techniques (K Nearest Neighbor, Artificial Neural Networks, Random Forests, Support Vector Machines, Naive Bayes) are compared. In addition to traditional time domain motion representations, a novel space domain representation is put forth which results in a two order of magnitude reduction in computational complexity. A case study dataset is created from 11 individuals performing 10 repetitions of 10 different upper body exercises. A single bicep mounted smart phone is used for data collection and both action classification and non-action rejection ability are studied.