Design Space Exploration of FPGA-Based Deep Convolutional Neural Networks
Abstract
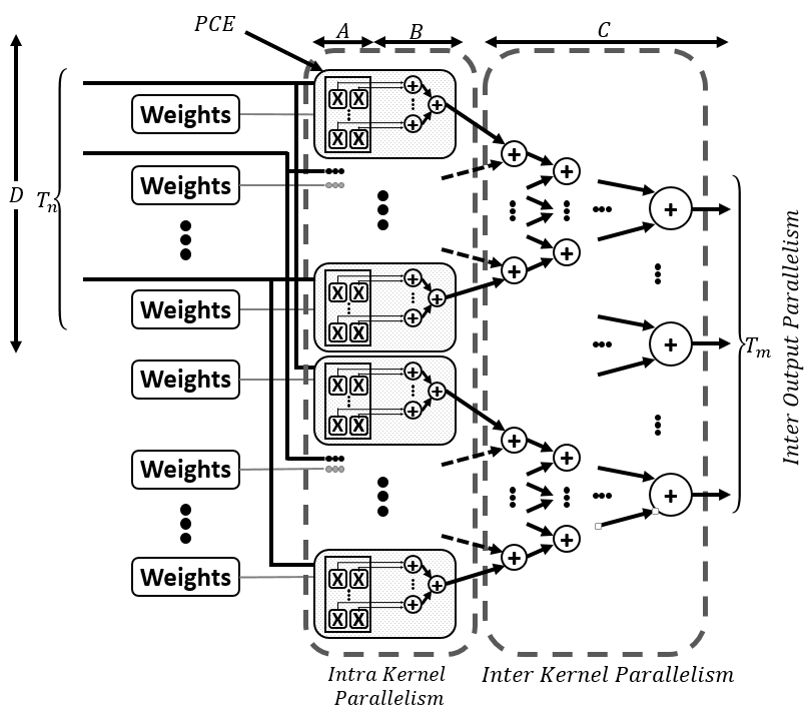
Deep Convolutional Neural Networks (DCNN) have proven to be very effective in many pattern recognition applications, such as image classification and speech recognition. Due to their computational complexity, DCNNs demand implementations that utilize custom hardware accelerators to meet performance and energy-efficiency constraints. In this paper, we propose an FPGA-based accelerator architecture which leverages all sources of parallelism in DCNNs. We develop analytical feasibility and performance estimation models that take into account various design and platform parameters. We also present a design space exploration algorithm for obtaining the implementation with the highest performance on a given platform. Simulation results with a real-life DCNN demonstrate that our accelerator outperforms other competing approaches, which disregard some sources of parallelism in the application. Most notably, our accelerator runs 1.9X faster than the state-of-the-art DCNN accelerator on the same FPGA device.
Download
Local Copy Download [PDF]
Presentation Download [PDF]
