Deep Convolutional Neural Networks (DCNNs) are one of the most effective classification methods which are used successfully in different classification and recognitions tasks. DCNNs especially have very astonishing results in image classification and recognition tasks.
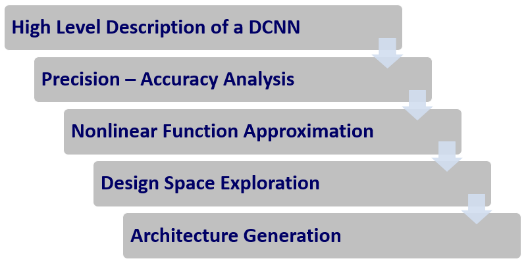
However, DCNNs involve intensive computations, and their software implementations incur considerable execution time and energy dissipation. Hardware accelerators are arguably the most promising approach to address both execution time and energy consumption issues. However, designing a hardw
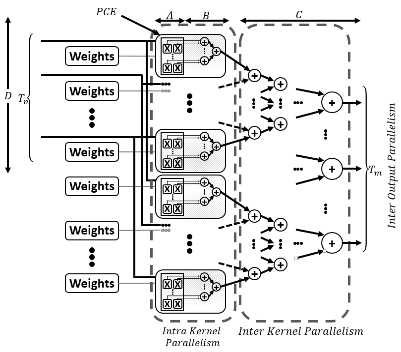
are accelerator is very complicated and time consuming. In this project, Prof. Ghiasi and his group are developing a toolset which is able to design an optimal FPGA based accelerator for any given DCNN on a particular FPGA. The toolset analyzes the precision – accuracy tradeoff in order to find an optimal bit width for the implementation. Moreover, it is able to simplify the computational complexity of the DCNN without major loss in the accuracy. After analyzing the input DCNN, the toolset uses an efficient architecture template which is designed to be able to utilize all parallelism sources which are available in DCNNs. Based on this template, the toolset explore the design space to find the optimal architecture with yields the highest throughput.
Related publications:
- Mohammad Motamedi, Philipp Gysel, Venkatesh Akella and Soheil Ghiasi, “Design Space Exploration of FPGA-Based Deep Convolutional Neural Network”, IEEE/ACM Asia-South Pacific Design Automation Conference (ASPDAC), January 2016.