On Resource-Efficient Inference using Trained Convolutional Neural Networks
We are pleased to release new results on approximation of deep Convolutional Neural Networks (CNN). We used Ristretto to approximate trained 32-bit floating point CNNs. The key results can be summarized as follows:
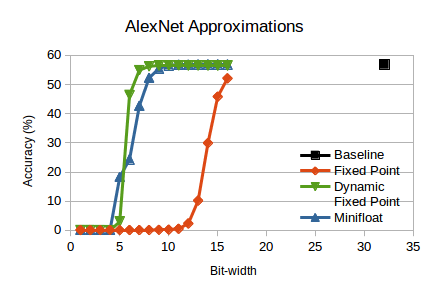
- 8-bit dynamic fixed point is enough to approximate three ImageNet networks.
- 32-bit multiplications can be replaced by bit-shifts for small networks.
Continue reading “On Resource-Efficient Inference using Trained Convolutional Neural Networks”